Have you ever faced the challenge of managing hundreds of Power BI reports and found yourself unsure about the data sources they connect to? I offer a straightforward solution which is tested in the real world – extracting data from Power BI reports with Python and Power Automate.
Essentially, we are going to build a Python script and Power Automate flow to automate the extraction of source, schema, and item information, significantly simplifying data management and enhancing both efficiency and accuracy
The Problem
We have hundreds of Power BI reports and we need to find which data sources they connect to.
Going over them one by one is too much of a hassle and a waste of time.
We need an automated solution that could be used with a variety of reports.
The Potential Solution
The Source data (which involves Source, Schema, Item, etc.) is available in .pbit files. More importantly, in the DataModelSchema file which is essentially a JSON structured file. The annoying part is that all we have are .pbix files.
We have to:
- Take the .pbix files and turn them into .pbit files.
- Then, change all of the .pbit file extensions into .zips. Or in other words – turn them into .zip files.
- And finally, extract the Source information from the DataModelSchema files which are essentially JSON files that have our precious data in them.
Sounds simple enough? Not really but let’s do it!
Using Power Automate Desktop to Transform .pbix Files into .pbit Files
I used this video as a basis here: https://powerusers.microsoft.com/t5/Power-Automate-Cookbook/Automate-the-process-of-exporting-Power-BI-files-pbix-to/td-p/489910
I made some modifications and will share them in this blog post.
Important things you need to consider:
- You can only use Power Automate Desktop. The Cloud version won’t suffice.
- You need a Power Automate licence to use the Desktop version.
Creating the first Power Automate Flow
Once Power Automate desktop is installed, you are ready to create the first flow needed for our automation task.
I will now list the steps via screenshots and will explain the most important ones.
Some important things to consider before jumping in:
- Using the Desktop version of Power Automate can be cumbersome and recording the steps yourself takes time. You will have to go over and over because the entire process regarding recording actions is a bit “in BETA” mode.
- For example, the recorder doesn’t recognize some of the elements right of the bat.
- If you update Power BI desktop for example – you need to rerecord most or a lot of the steps! Keep this in mind!
Creating Global Variables for our Flow in Power Automate Desktop
In order to avoid manual labour, we need to create a couple of variables to ease our process later. None of us wants to type in the file and file path names manually.
We have 4 variables:
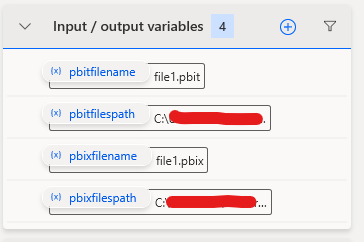
Each needs their own unique values:
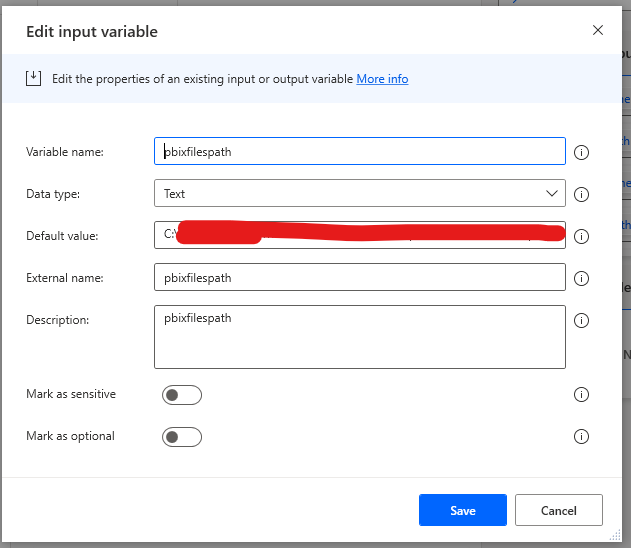
Make sure you fill in the Default value input with the path to your folder where your .pbix files are located!
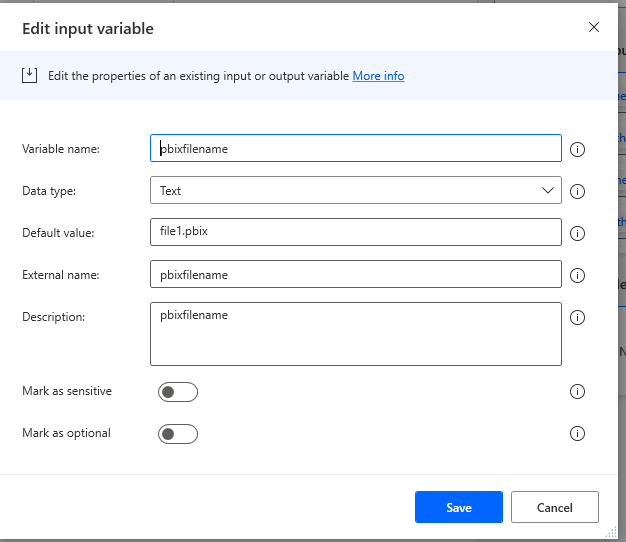
You can leave the file values hardcoded for now. We will automate this process with our second flow later.
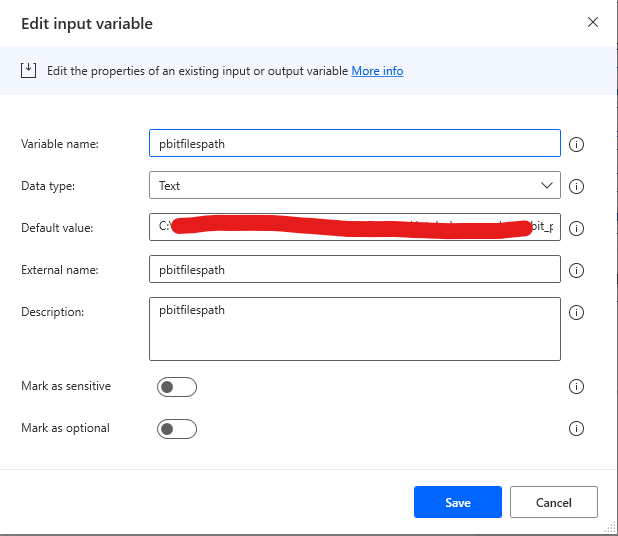
Similar with the .pbit file path.
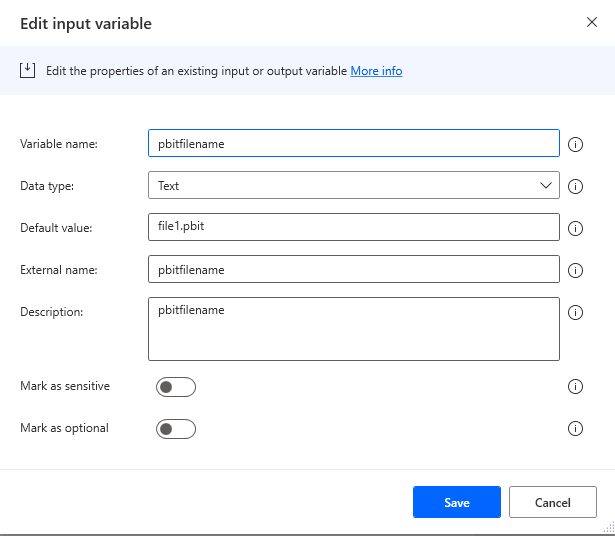
And file.
The First Steps in the Flow
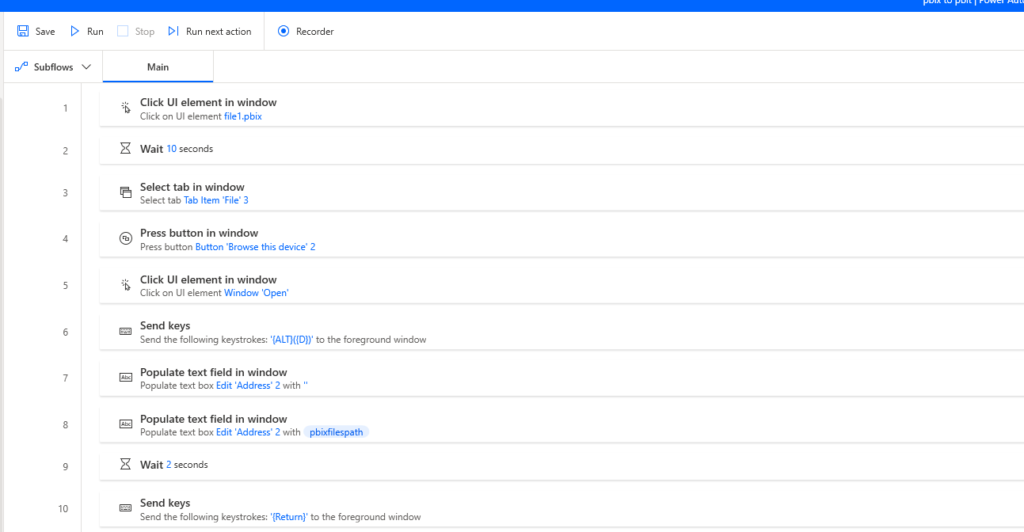
- I created a blank file for the flow because just opening Power BI desktop was too much of a hassle.
- This means, that on your desktop there should be a Power BI desktop file (.pbix) named “file1.pbix”.
- Power Automate will then just click it open to get to the next steps which involve transforming .pbix
- The wait 10 seconds is there to wait for the file to open before proceeding to the next steps.
- Number 3 is clicking on the “File” menu element to open the files we actually need to transform.
- In task number 4 we click on the “Browse this computer button”.
- Step number 5 actually just clicks on the “Browse files” window.
- Otherwise, we can’t select the address bar.
- We send ALT + D to the Window we just clicked on. With that, selecting the address bar.
- I recommend you use “Send keys” – selecting the windows with the recorder didn’t work! I had to select the windows each time I ran the flow again and again. Power Automate seems to forget which UI element it needs to select and click on. But “Send keys” works.
- The expression syntax is: {ALT}({D})
- In step number 7 we delete the address field.
- After the address field has been deleted we can now populate it with the variable we created earlier called “pbixfilepath”.
- The expression syntax: %pbixfilespath%
- I added a tiny wait as step 9 because Power Automate needs to wait for the path to populate.
- Step number 10 is pressing enter for the path and location to be activated.
Next Steps in the First Power Automate Flow
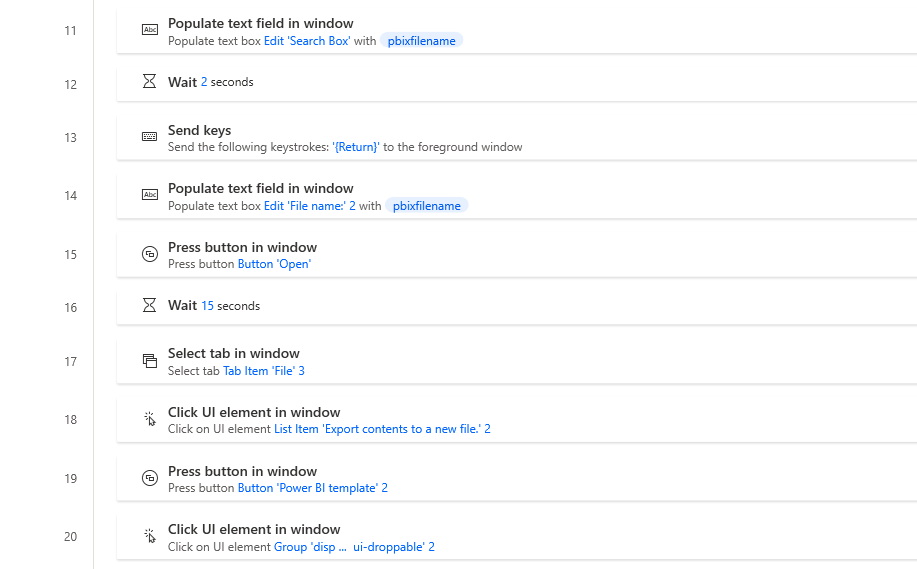
- We enter the name of the .pbix file name using the variable we created earlier into the search box.
- Wait 2 seconds for the name to be written.
- Click enter for the search to start.
- Populate the file name input with the pbixfilename variable.
- Press open.
- We have managed to open the actual file we need to transform from .pbix to .pbit. Hooray for us!
- And this is where it gets tricky with Power Automate – or I should say, tricker.
- Wait for the new file to open.
- Click on File menu button.
- Click on the Export menu item.
- And click on the Power BI template menu button.
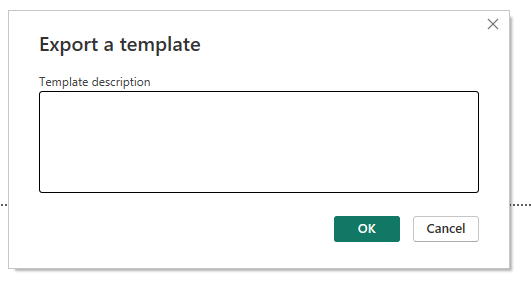
- This is where it gets really messy because the aforementioned Template description window pops up (already shown above).
- Try clicking (and this is what I mean, you will understand in a second…) on the Template window.
The Trickier Part of our Power Automate Flow
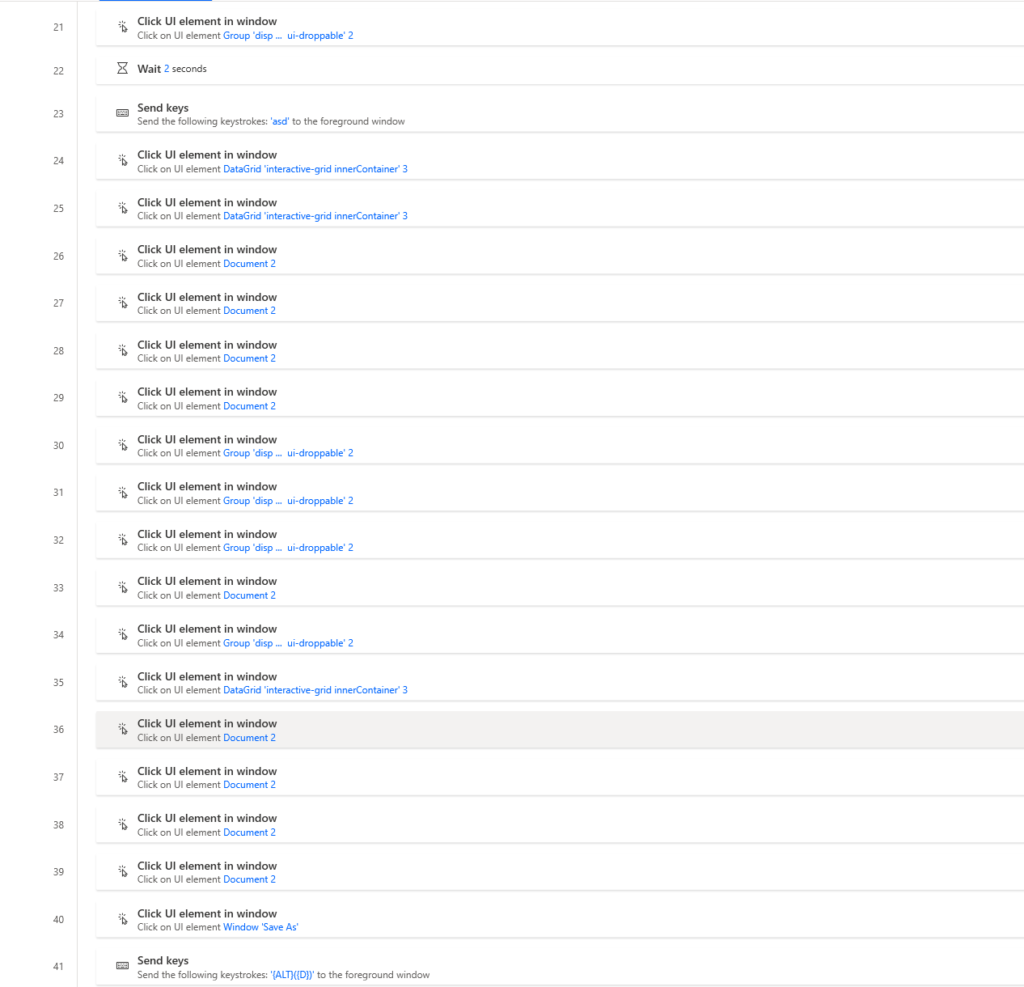
- We try to click again.
- Another wait to trick Power Automate into recognizing the Template window.
- Send keys into the Template window to trick Power Automate again.
- Steps 24-39 are all just tries to click on the Template window to close it to get the Save as window open. Whatever you can do to click on it and activate it – do it.
- Step number 40, here we finally got the Template description window closed and have the Save as window open. And we click on it.
- Again send CTRL+D to activate the address toolbar.
Finalizing Our First Power Automate Flow
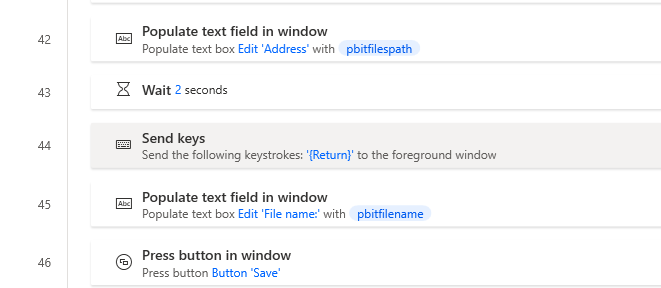
We have almost done it but we still need to save the file as a .pbit file.
- Enter the pbitfilespath variable into the address input field.
- Wait 2 seconds for Power Automate to populate it.
- Press enter.
- Populate the text in the File name: input with pbitfilename variable. Which will be file1.pbit for now. Later we will loop through all the files in our folder to give names automatically to the new files.
- Press the Save button.
Optional here is to add steps to close Power BI windows within the Flow but it turned out to be more difficult than one might imagine at first.
The problem is similar to the Template description window. Power Automate seemingly forgets which window it selected. It would make sense that it treats all Power BI application windows the same but it truly doesn’t.
We have finally created the first important piece of the puzzle. On to the next Power Automate flow that will automate our process.
NB! Something important to keep in mind – when you have different sources, Power BI desktop also acts differently. Meaning, it will throw warnings here and there that you need to take into account. Basically, you need to create similar flows through copy-paste and some iterations if you have Power BI reports that have for example SQL server connections. Just because they behave differently and give different prompts.
Creating the 2nd Power Automate Desktop Flow
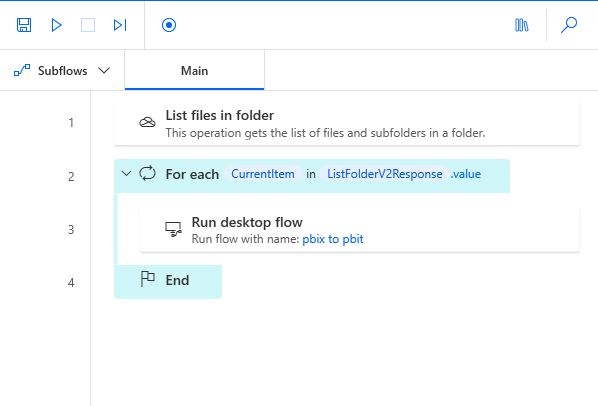
As you can see there are fewer steps in the 2nd flow – just because we will use our 1st flow in it!
- List Files in folder task.
- Here we need to define the path where our .pbix files are located. Then we need to save these files into a variable.
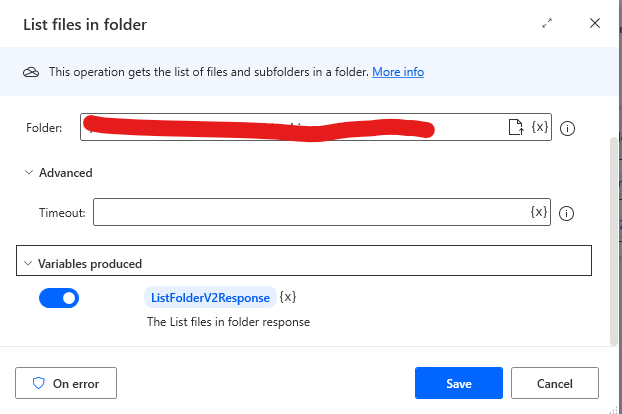
- Now we need to add a For each loop Flow task.
- This needs more setting up and we will use the variables created during the 1st Flow here.
- When we loop through the folder, we get a lot of information about our files. Make sure you iterate over the .value variable extension as seen in the screenshot.
- This is how it should look like %ListFolderV2Response.value%
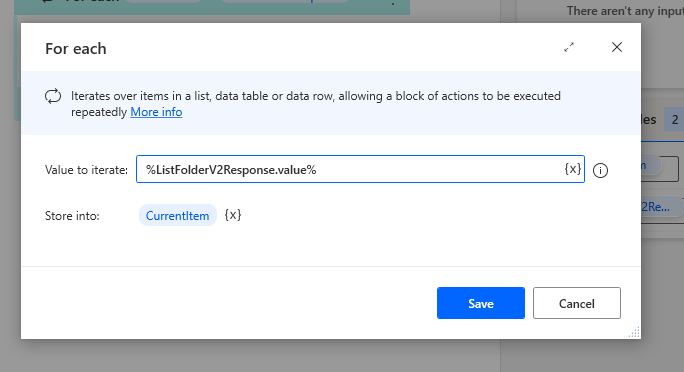
- Inside the For each loop, we need to place our Flow number 1.
- Make sure you choose the right flow under Desktop flow input field.
- You should now recognize and setup all the variables from Flow 1 here.
- Pbixfilename variable should have an expression of %CurrentItem.Name%. We are taking the name value of the variable we are iterating through the folder and the values are saved in the “CurrentItem” variable.
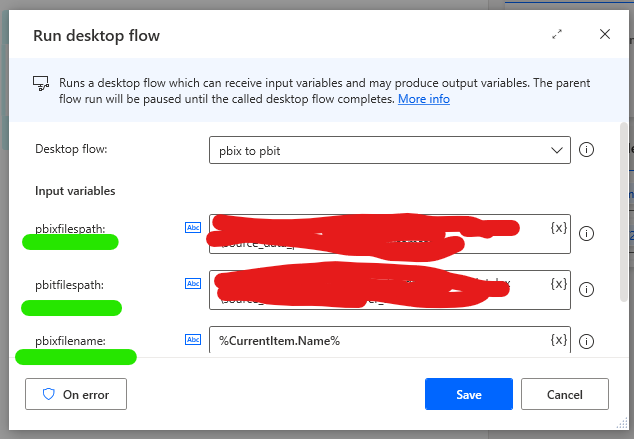
- We now also need to make sure we save the new files as .pbit files not .pbix files.
- It took some testing and trial and error but the end result that should be under the pbitfilename variable: %CurrentItem.NameNoExt%.pbit
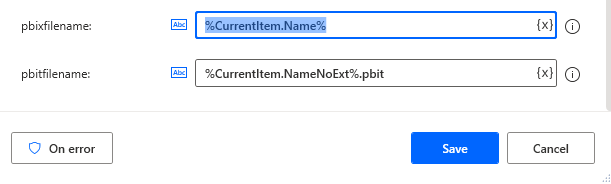
And that’s it! You have completed the first part of extracting data from Power BI reports with Python and Power Automate. Now for the so-called easy part.
The Python Script to Extract Data From .pbit Files
You can use git clone to clone the repo here.
Here’s the full code:
import os
import zipfile
import json
import pandas as pd
import shutil
# Get the information of the files. Make sure you set the encoding to utf-16-le, otherwise the data can't be read from the DataModelSchema files.
def extract_source_info(zip_path, encoding='utf-16-le'):
temp_extract_dir = "temp_extracted" # Creates the temp folder to store the extracted data to get the DataModelSchema file.
os.makedirs(temp_extract_dir, exist_ok=True) # Ensures the directory exists. If it doesn't we don't continue.
with zipfile.ZipFile(zip_path, 'r') as zip_ref: # Opens the zip file in read mode.
# Extracts files individually to handle potential long path issues.
for file_info in zip_ref.infolist(): # Goes through the files contained in the zipped archive.
# Construct the target path for the file
long_target_path = "\\\\?\\" + os.path.abspath(os.path.join(temp_extract_dir, file_info.filename)) # Used "\\\\?\\" to handle potential long file names.
# Ensure that the directory exists for the file to be extracted into.
os.makedirs(os.path.dirname(long_target_path), exist_ok=True)
# Extracts the file with shutil.
with zip_ref.open(file_info) as source:
with open(long_target_path, "wb") as target:
shutil.copyfileobj(source, target)
# Now, the files have been extracted, continue with loading the DataModelSchema. Also checks if the file exists.
schema_path = os.path.join(temp_extract_dir, "DataModelSchema")
if not os.path.exists(schema_path):
print(f"DataModelSchema file not found in {zip_path}") # If the file doesn't exist, displays an error.
return []
with open(schema_path, "r", encoding=encoding) as file: # Opens the DataModelSchema file with the specific encoding.
data_model = json.load(file) # Loadd the JSON content from the DataModelSchema file into a dictionary.
# Navigate to the 'model' key in the JSON structure and then to 'tables' to find 'partitions'.
if 'model' in data_model and 'tables' in data_model['model']:
tables = data_model['model']['tables']
# Flatten the list of partitions from all tables.
sources = [partition for table in tables if 'partitions' in table for partition in table['partitions']]
# Debugging: print the sources to see if they are being extracted correctly.
print(f"Extracted sources from {zip_path}:")
print(sources)
return sources
else:
print(f"No 'model' or 'tables' key found in {zip_path}")
return []
# Defines a function to rename .pbit files to .zip, extract source information, and collect this information in a list.
def rename_and_extract_sources(directory):
extracted_info = [] # Initializes an empty list to hold the extracted information.
for filename in os.listdir(directory): # Iterates over all files in the specified directory.
if filename.endswith(".pbit"): #C hecks if the file has a .pbit extension.
# Renames the .pbit file to .zip.
base = os.path.splitext(filename)[0]
zip_path = os.path.join(directory, base + ".zip")
os.rename(os.path.join(directory, filename), zip_path)
sources = extract_source_info(zip_path)
# Debugging: print the sources to see if the list is populated.
print(f"Sources for {filename}:")
print(sources)
for source in sources:
source_info = {
"File Name": base,
**source
}
# Debugging: print the source_info before appending.
print(f"Source info to append for {filename}:")
print(source_info)
extracted_info.append(source_info)
# Debugging: print the final extracted_info to see if it's correct.
print("Final extracted information:")
print(extracted_info)
return extracted_info
# Saves the needed information from .pbit and the generated .zip files into an Excel spreadsheet.
def save_to_excel(extracted_info, output_file):
df = pd.DataFrame(extracted_info) # Saves the DataFrame to an Excel file without the index column.
# Debugging: print the DataFrame to ensure it's not empty.
print("DataFrame to be saved to Excel:")
print(df)
df.to_excel(output_file, index=False)
# These lines set the directory to process, call the function to rename and extract sources, and then save the extracted information to an Excel file named output.xlsx.
directory = "C:/Users/YourDirectory"
extracted_info = rename_and_extract_sources(directory)
save_to_excel(extracted_info, "output.xlsx")
That’s it! We have now transformed our .pbix files into .pbit files and extracted the valuable information from them.
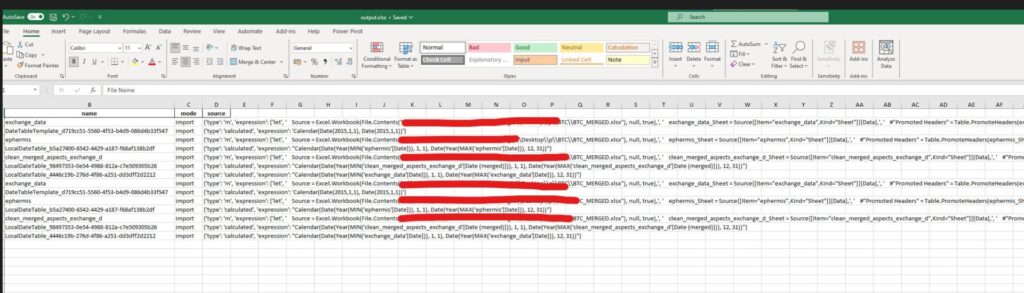
The End Result of Extracting Data from Power BI Reports with Python and Power Automate
If the Tech Gods have smiled upon you – you should have something like this:
Some of the things mentioned in this post I learned from the Zerto To Mastery academy here. If You decide to sign-up, I will earn a commission.